
Azure Data Factory with practical example
Azure Data factory is the data orchestration service provided by the Microsoft Azure cloud. ADF is used for following use cases mainly :
- Data migration from one data source to other
- On Premise to cloud data migration
- ETL purpose
- Automated the data flow.
In this article we will see step by step guide to create the Data pipeline using the azure data factory where we will move the CSV data from the azure blob storage to Azure Sql database.
Before moving to the example lets understand the elements of the azure data factory.
You can find detailed video with step by step here :
Data Source : It is the source system which contains the data to be used or operate upon. It could be anything like text, binary, json, csv type files or may be audio, video, image files, or may be a proper database.
Linked Service : You could be think of it as the key (like key to open lock) which helps to authenticate the access to the data source. For example in case of database as data source, linked service would be created using the db user name and password. When you need to connect to data sources, it would be done using the linked service.
DataSet : Dataset is the representation of the data contains by the data source. For example the Blob binary data set is representing the binary file in the azure blob storage. For creating the dataset, linked service need to created first. Dataset through linked service access the data in/out from the data source.
Activity: Acitvity represents the operation that need to be performed on the data. There many activities available in azure data factory. Most common activity is the Copy Activity , it represent that, data has to be copied from source to destination.
Pipeline : It is the logical grouping of the activities to perform certain tasks. It helps in creating the logical/sequential flow of the task need to be performed to achieve certain goal.
Integration Runtime : It is the powerhouse of the azure data pipeline. It provides the compute resource to perform operations defined by the activities.
Azure data factory example to copy csv file from azure blob storage to Azure sql databse :
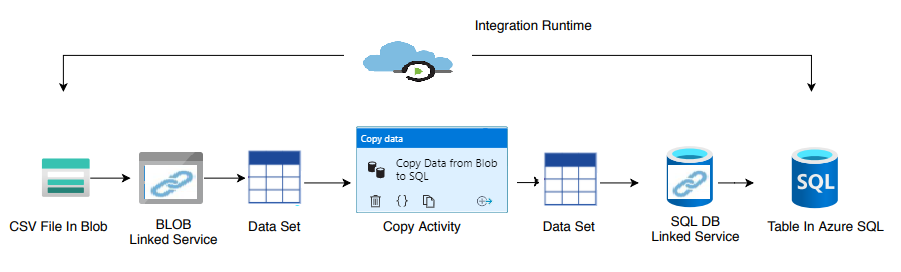
Elements need to create :
Linked Service : 2 Linked service need to be created. One for connect to blob (source) and second one for Azure Sql db (destination).
DataSet : 2 Dataset need to be created . One for blob and second for Azure sql db.
Activity : Only one activity i.e. copy activity need to created.
Pipeline : A pipeline will be created containing the copy activity.
Integartion Runtime : We will use auto resolve integration runtime provided by azure data factory itself.
Assumptions : We assumed that blob storage container and azure sql database is already exist.
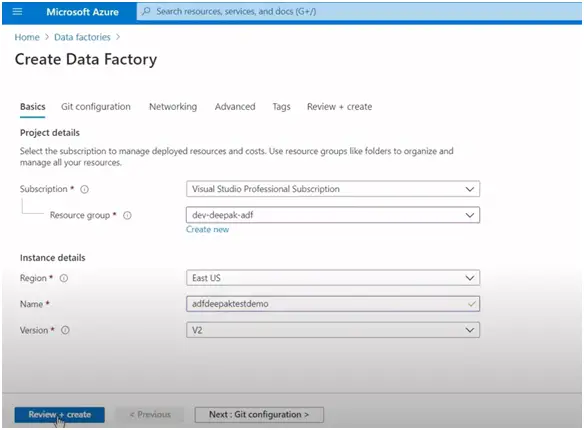
Go to azure portal and create the azure data factory account :
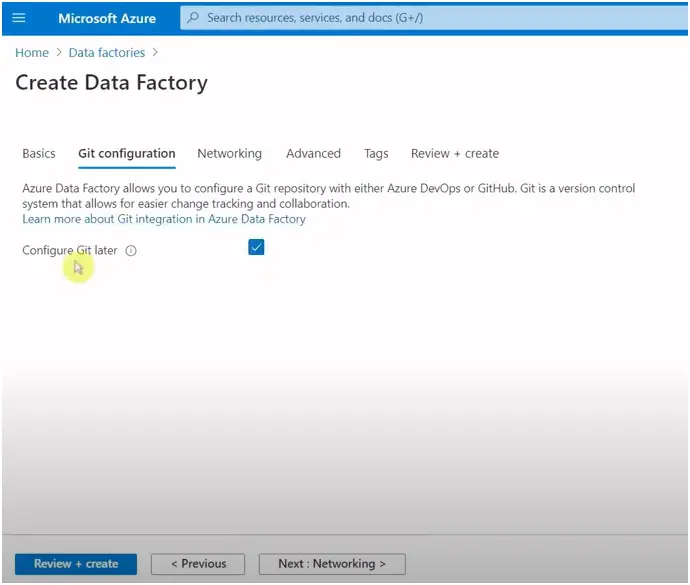
Check the configure Git later
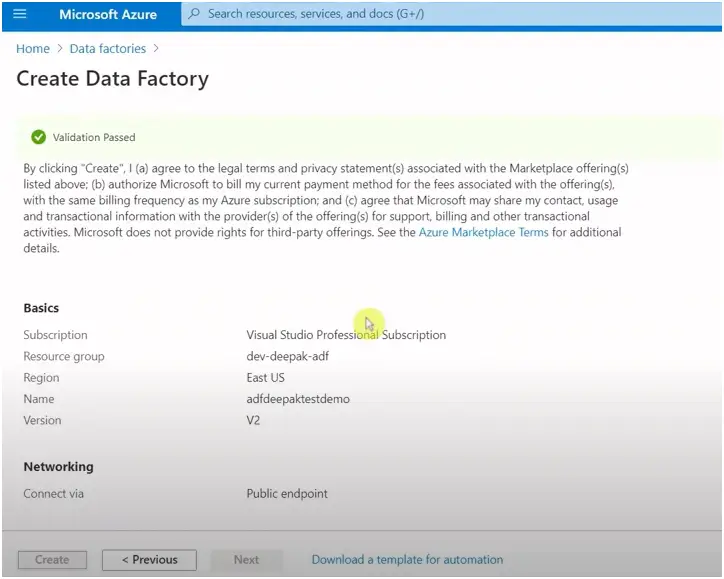
Keep everything else as it is and click Review+create.
This will create the azure data factory account.
Now go to the newly created azure data factory account and click author and monitor:

You will be greeted with following screen :
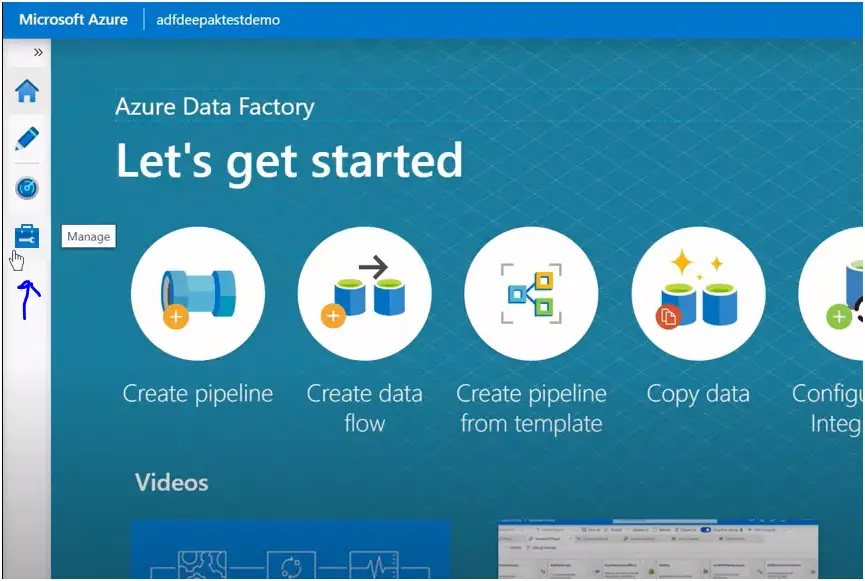
Click on the Manage Tab to create the linked service.
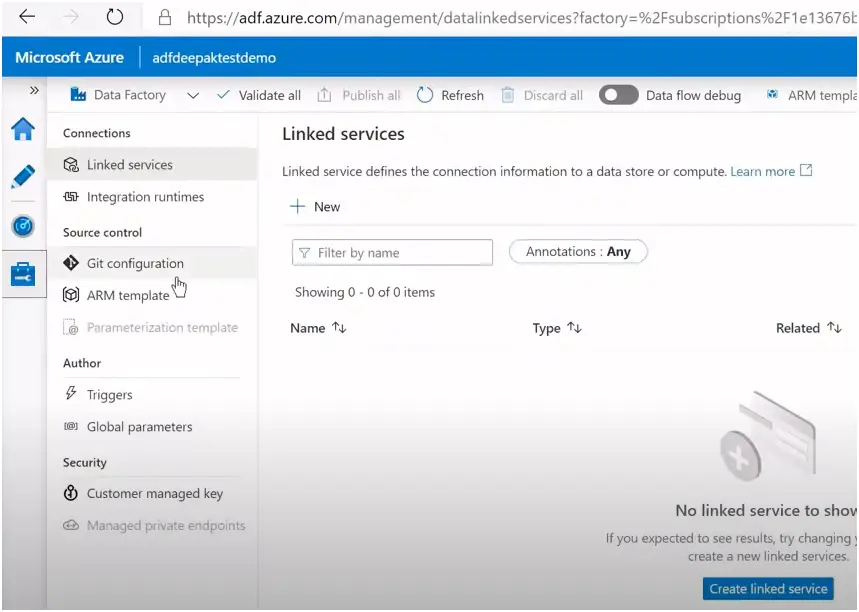
Click on + New or Create Linked Service for creating the linked service.
Based on the data source select the type. In our case it is blob storage :

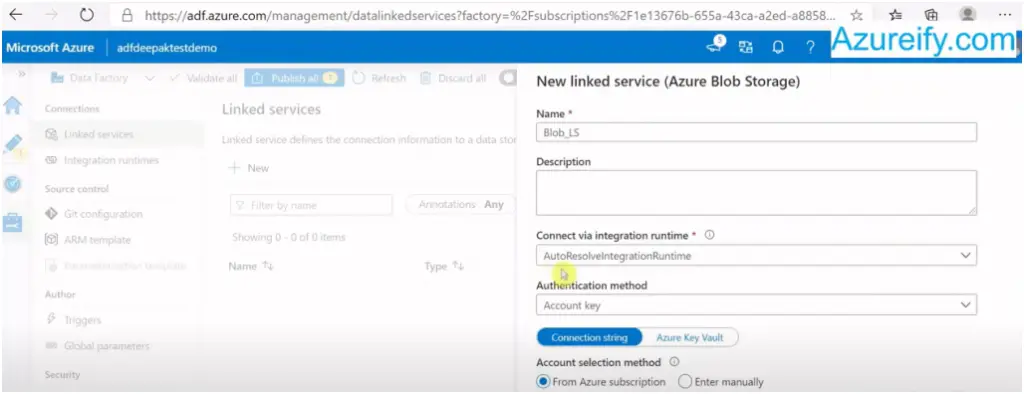
Provide the details, test the connection and create the linked service:
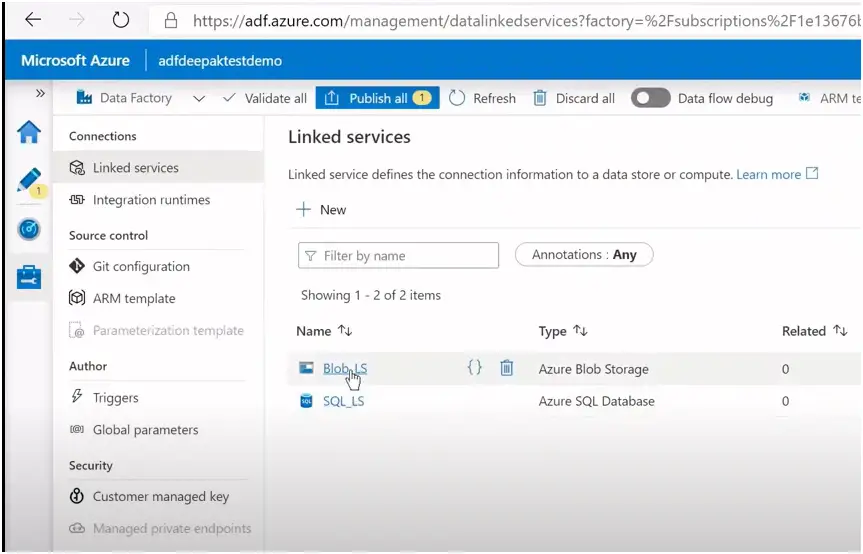
Follow the same procedure for creating the second linked service for azure sql database.
You can flow this video as well :
Now create the pipeline and data set by going to author tab :
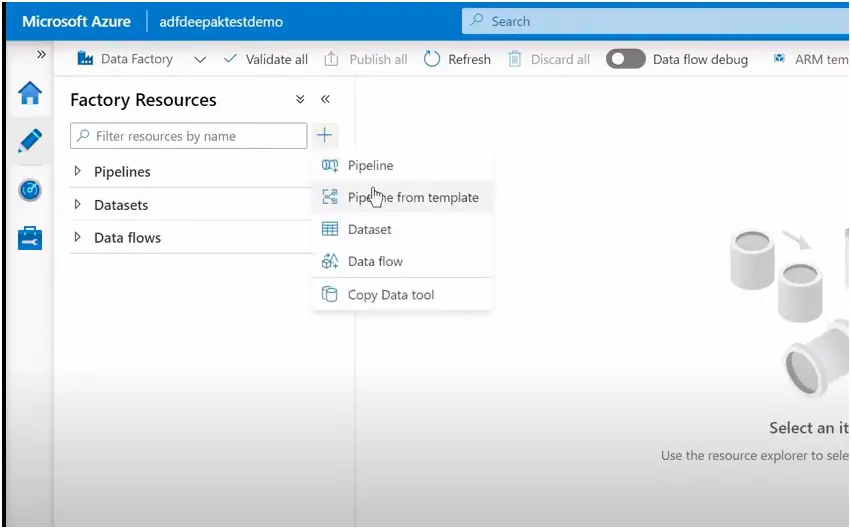
First create the pipeline by clicking on + sign and create pipeline :
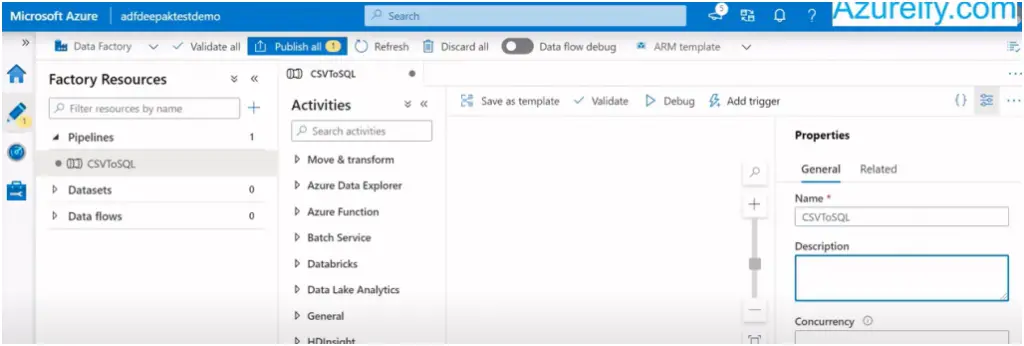
Provide the pipeline name and description :
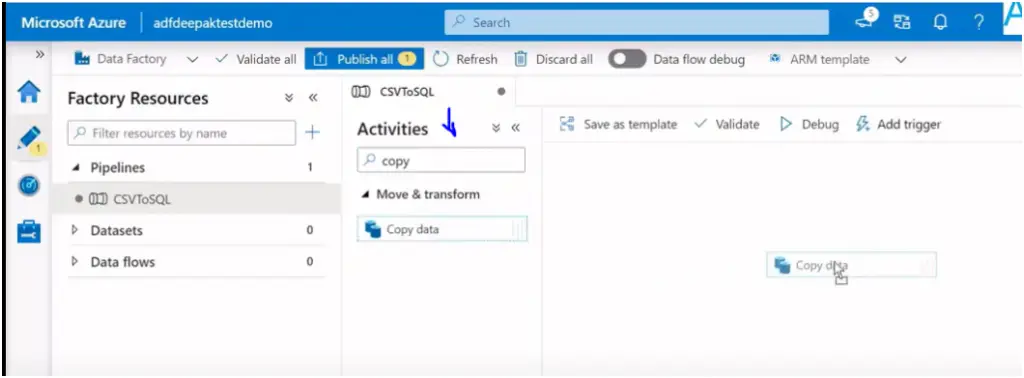
Now add the copy activity by searching the copy activity in the highlighted box. Drag and drop activity to pipeline designer :
In Copy activity we need to provide the source and destination in the form of the dataset. Click on + sign to create the dataset:
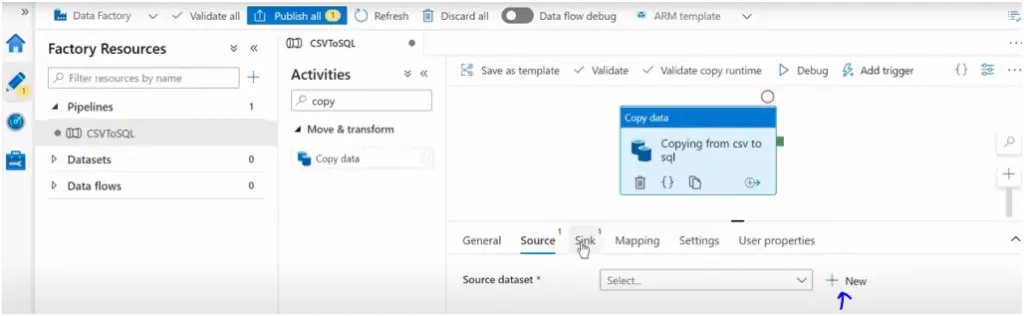
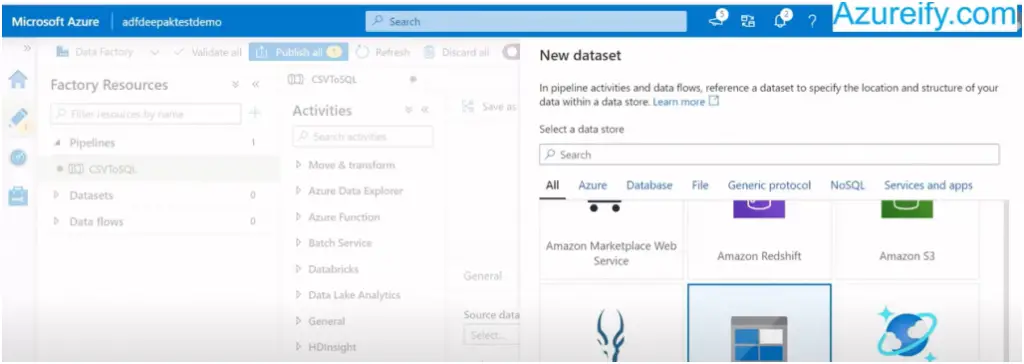
Select the type of the data store. For first data set (input data source) the data store is of blob storage type, select and click continue :
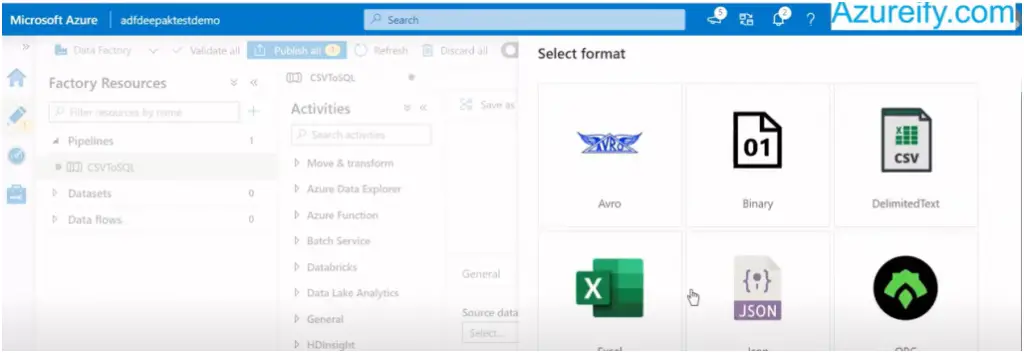
Now select the data format, in our first case it is csv file :
Now provide the dataset name and the linked service to connect to data source :

Similarly create the second dataset to connect to azure sql db.
You can flow this video as well :
Select the newly created dataset for source and sink in the copy activity.
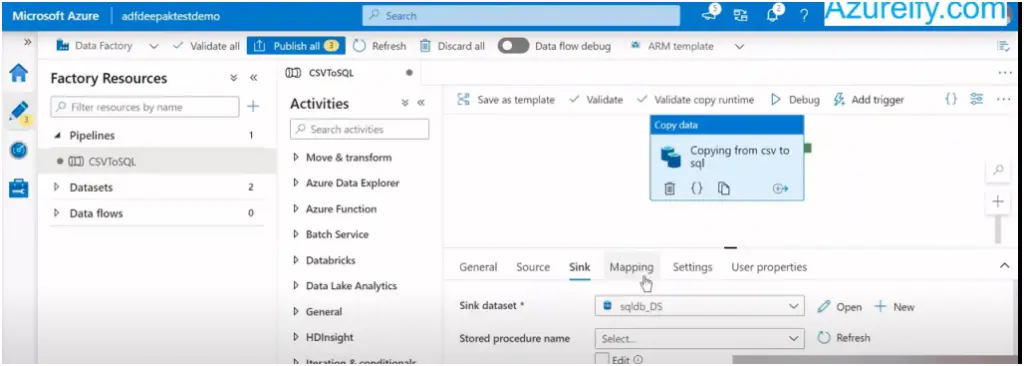
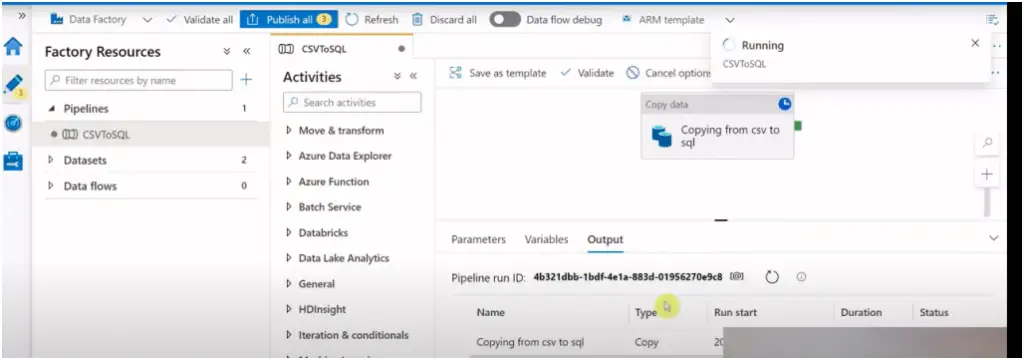
Now your pipeline is ready to run, first click on debug to test and once everything looks ok click on Publish button to save the changes and publish it for group.
Hope you find this article helpful, in case if you have any issues or queries please out them in comment box below. I will try to answer them as early as possible.
