
In this series of Azure Databricks tutorial I will take you through step by step concept building for Azure Databricks and spark. I will explain every concept with practical examples which will help you to make yourself ready to work in spark, pyspark, and Azure Databricks. I will include code examples for SCALA and python both. In this series we will learn spark and Databricks as both as these are really overlapping topics Databricks is something that uses apache spark under the covers.
Lesson 2: Azure Databricks Spark Tutorial
- Azure Databricks Lesson 1
- Azure Databricks Lesson 2
- Azure Databricks Lesson 3
- Azure Databricks Lesson 4
Prerequisite for Azure Databricks Tutorial
There is as such no perquisite for this tutorial guide. However I would have few recommendation:
- Basic computer knowledge.
- Understanding of any basic programming language
Big data analytics before Apache Spark
Let’s first cover history behind the origin and popularity of the Azure Databricks.
What is hadoop ecosystem
Hadoop is the first big data platform open source available. After over time other services and tools were added to this hadoop project. Though these big data services have nothing really to do with hadoop so they broadened apache hadoop project. This is a little inefficient as earlier it was a single product that was hadoop but now we have an entire project which is hadoop. Basically Hadoop consists of the HDFS and the Mapreduce.
HDFS stands for the Hadoop distributed file system. It is mainly developed to store the data across the cluster in the distributed format. Your computer file system used to store the files and directory on your computer and laptop. Similarly to store the file in the distributed format all over the multiple nodes in the cluster HDFS is used.
Map reduce is the framework available in hadoop to write your analytics logic and run it over hadoop cluster. In the map reduce framework, you write the logic in terms of the mapper and reducer task. Mapper task run for every block or partition of the data. All the mapper task data will be aggregated by the reducer task.
What are the limitation of Hadoop over Spark
- Hadoop doesn’t support the interactive queries, it only provides the batch processing.
- Writing the map reduce job is very difficult and complex in nature. It is not easy for any newbie to start quickly on map reduce logics. Code is lengthy and supports Java, python majorly. Though we can write the map reduce logic in the C++ but it does not work that well.
- Biggest disadvantage of Hadoop is its execution speed. Hadoop reads and writes the data in the disk. That makes it very slow when we have big data to process and analyze.
Understand what is Scale in/out and Scale up/down. Why it is important for Big data analytics.
I am going to use this Bag analogy which I am going to call scale up scale out with Bag. Here single Bag represents the legacy approach to scaling which is called scale-up and scale down. In the old days the technology worked like that only. When you have more work you opt for increasing the size of the hardware like increasing the RAM, disk number of processor. Once you don’t need it you will remove extra disk or RAM. But we reached a sort of point where we couldn’t expand fast enough for our needs, especially in the area of big data. We have hardware limitations to increase the disk size or RAM size after a certain point of time
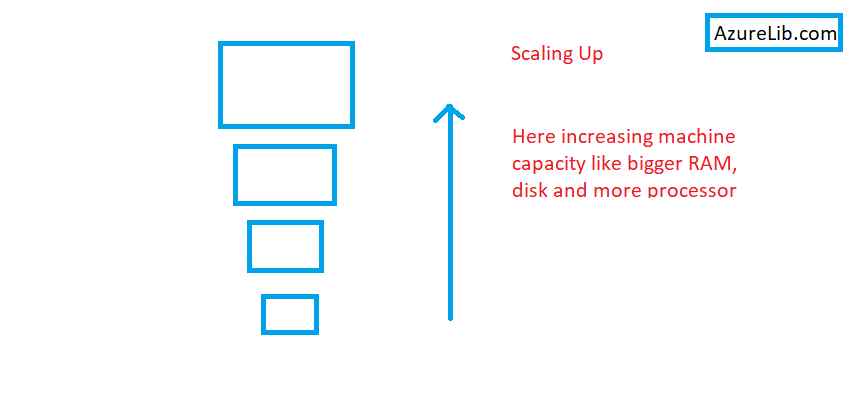
Companies like Google also had this problem before almost any other company did but now this problem is its own Companies like Google also had this problem before almost any other company did but now this problem is its own pandemic. It’s a problem across the globe being able to support all different types of data video imaging sound log files that have billions and trillions of rows and on. How do we handle this kind of workload once we reach the end of the scaling up?
Solution to this problem could be instead of having one person or machine try to do all the work, what if we took a given job and we partitioned it. We broke up the job and then we had a group of machines all work together to do it and this group of machines didn’t have to be like very big powerful machines, it could be ordinary commodity machines. This is called scale in and scale out.
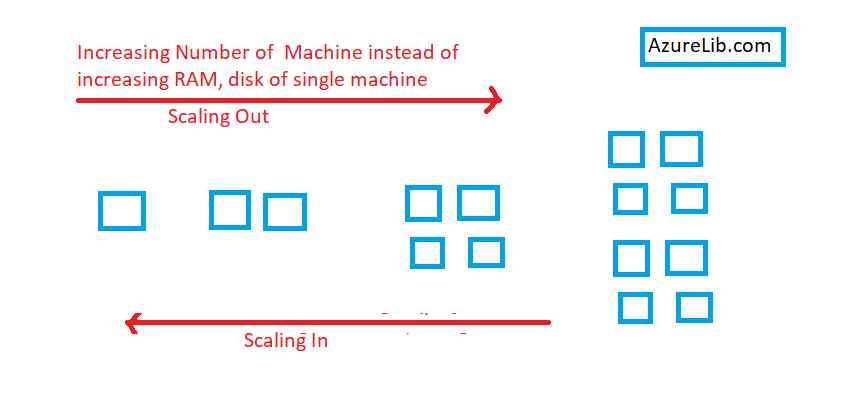
Example of Scale in Scale Out
So let’s see how that works. Imagine we have something like a phone book and what we want to do is find out everybody who’s living on main street. You go look through the phone book, if one person did this this is going to take a long time they’re going to have to go through the whole phone book.
But what if instead of doing that, you said we’re going to break up the phone book we’re going to separate it. It is already sorted by last name so what if we just take the first letter of the last name and we break up the phone book that way one person gets the a’s, b’s, c’s and so on. Then we ask them to do the search now, each person is going to have their own section they’re going to tally up how many occurrences they find and then there’s going to be the person who collects back the results.
So they’re going to collect back all by one person and this person will do the grand total. It is example of scale out and if you think of instead of people replace that with machines then your scale of technology and you can think of these machines they call them nodes and they don’t have to really be physical machines but if you think of them as separate running processes that’s good enough.
Well somebody made a request to them to do this right, they said this is what I need you to do guys that person is called playing the role of the cluster manager. So the cluster manager made the request and those results go back to that cluster manager to be consolidated and handed back to what’s called the driver context or the context.
Most important takeaway here is that instead of one machine doing the work alone, the work is being distributed among any number of machines. Separate processes running on separate machines as opposed to one machine.
Difference Between Apache Spark and Azure Databricks
What is Apache Spark and its limitation compared to Azure Databricks
Well the simplest answer is to say it’s the most actually popular open source big data platform for data science. When I say big data, this includes things like streaming video, images, structured and unstructured data and of course also a large volume of data that is typically something you couldn’t handle well with legacy technologies. Apache Spark provides an awesome powerful platform for your data processing but it does not give you any extra tools so you have no IDE (Integrated development Environment). It just provides raw bones and it has pretty weak support for collaboration. Lastly it’s not optimized for the cloud and if you’re paying attention to what’s happening these days everything’s going cloud so spark is a little bit behind in that. It can run on the cloud and in fact it does and we’ll see that as like for instance HDinsight on azure but it’s not optimized it wasn’t designed for that environment.
What is Databricks and its advantage over Apache Spark
It is a commercial product not open source, which is created by the developers of apache spark. There’s the company called Databricks and the product they have is also called Databricks, so these people who founded that company created databricks. Databricks is really meant as a complementary service around apache spark. It’s a complete development environment designed to get you up and running quickly with spark. It has numerous proprietary spark enhancements. Databricks is an ideal for data science team collaboration. It is designed for any size but large team collaboration is especially good for it. When you think about data science teams you really have to think of a diverse set of people. It’s not just data scientists you’ll have data engineers, you’ll have domain experts in the given business especially when you think of like healthcare or something there’s going to be people who really understand the domain. You are also going to have business analysts, maybe extra programmers and people focused on things like deployment and devops and then of course key to this whole thing would be people who are more like statisticians and data scientists.
Databricks is designed for bringing that all together and multiple data science teams on single common platform. There is a lot of powerful tools that databricks brings to the table as I mentioned. However on the other side spark has no such kind of facility. Databricks is a handy tool where the database is optimized. It runs over cloud. In fact it only runs in the cloud so if you say I want to run Databricks, If you ask me how I can run Databricks on-premise, I would say it’s not possible as of today while writing this article.
Now as we have understood the difference between spark and databricks which essentially is a I think that is a big wrap around spark giving you jump start access and tools.
Benefits of Azure Databricks for Data Engineers and Data Scientists
- It is highly performance optimized by caching, indexing, and advanced query optimization. All these helps to improve performance by as much as 10-100x over traditional Apache Spark deployments in cloud or on
- Azure Databricks team has partnered with Microsoft to develop and provide the high speed connectors to Azure Storage services such as Azure blob storage, Azure Data Lake Gen1 , Azure Data Lake Gen2.
- Auto-scaling and auto-termination for Spark clusters to automatically minimize costs of running the cluster unnecessarily.
- -Azure databricks allowed the facility to share the notebook within the team. This will make life much easier because now the collaboration within the team can be possible in real-time.
- Azure Databricks is backed by Azure Database and other technologies that enable highly concurrent access, fast performance and geo-replication. All these help Azure Databricks integrate closely with PowerBI for interactive visualization.
- Azure Databricks comes with interactive notebooks that make it very easy to connect to any data source, run complex machine learning algorithms very quickly.
- It has an integrated debugging environment to let you analyze the progress of your Spark jobs from within interactive notebooks, and powerful tools to analyze past jobs.
Azure Databricks Architecture
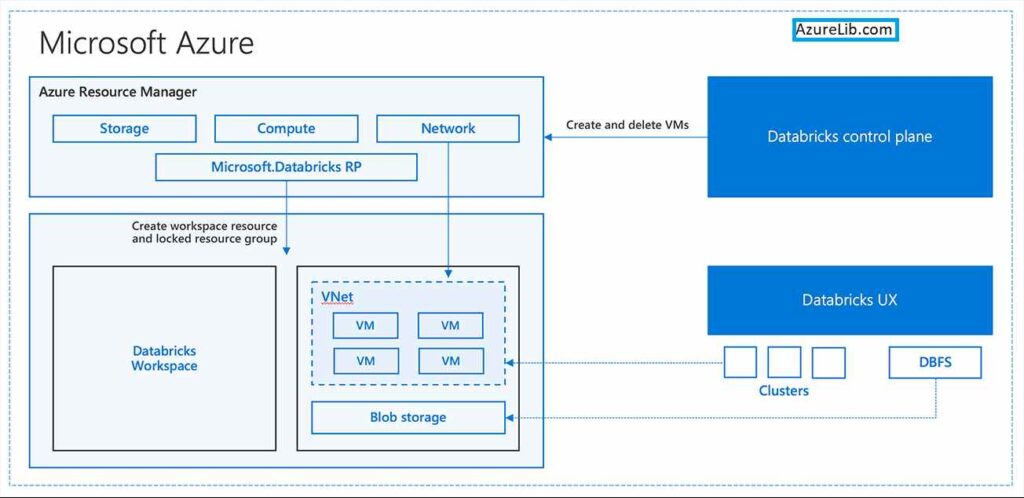
This is a high level understanding of the Microsoft Azure Databricks. However as a Databricks developer, or data engineer or data scientist you don’t have to worry much about it. It is just representation of how Databricks and Azure internally interconnected to each other. It has nothing to do with how you would write your queries and logics.
Final Thoughts
In this first lesson of our Azure Databricks Spark tutorial we have learned, why spark was needed, difference between the Apache spark and Databricks. We have also learned what is scaling in/out and scaling up/down. Azure Databricks has a couple of advantages over spark. It is going to be very crucial for the new data engineer to understand these Azure Databricks concepts.
