
In this lesson 4 of our Azure Spark tutorial series I will take you through Apache Spark architecture and its internal working. I will also take you through how and where you can access various Azure Databricks functionality needed in your day to day big data analytics processing. In case you haven’t gone through my first Lesson 1 of Azure Databricks tutorial, I would highly recommend going to lesson 1 to understand the Azure Databricks from scratch. For creating your first Azure Databricks free trial account follow this link : Create Azure Databricks Account. Let’s dive into the tutorial now.
- Azure Databricks Lesson 1
- Azure Databricks Lesson 2
- Azure Databricks Lesson 3
- Azure Databricks Lesson 4
- Azure Databricks Lesson 5
- Azure Databricks Lesson 6
- Azure Databricks Lesson 7
Apache Spark’s Distributed Parallel Processing Components
Spark is a distributed data processing which usually works on a cluster of machines. Let’s understand how all the components of Spark’s distributed architecture work together and communicate. We will also know what are the different modes in which clusters can be deployed.
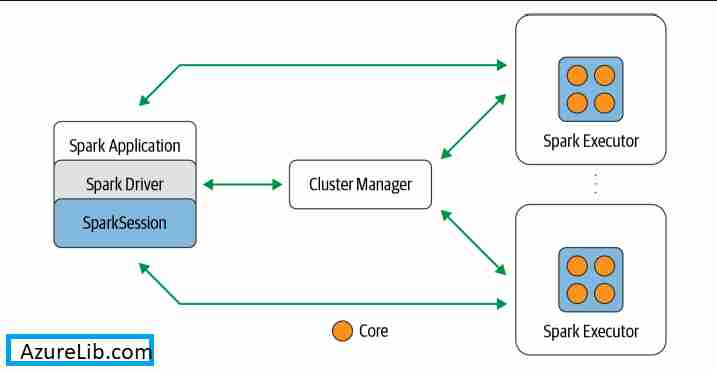
Spark Components
Let’s start by looking at each of the individual components in Spark architecture.
Spark Driver:
Basically every Spark Application i.e. the spark program or spark job has a spark driver associated with it. This Spark driver is the one who has the following roles:
- Communicate with the Cluster manager.
- Request Cluster manager to get the resources (CPU, Memory) for Spark executor.
- Transforms all the Spark operations into DAG computations.
- Distribute the task to the executor
- Communicate and take the status of the task from the executor directly.
The driver process is absolutely essential – it’s the heart of a Spark Application and maintains all relevant information during the lifetime of the application.
- The Driver is the JVM in which our application runs.
- The secret to Spark’s awesome performance is parallelism:
- Scaling vertically (i.e. making a single computer more powerful by adding physical hardware) is limited to a finite amount of RAM, Threads and CPU speeds, due to the nature of motherboards having limited physical slots in Data Centers/Desktops.
- Scaling horizontally (i.e. throwing more identical machines into the Cluster) means we can simply add new “nodes” to the cluster almost endlessly, because a Data Center can theoretically have an interconnected number of ~infinite machines
- We parallelize at two levels:
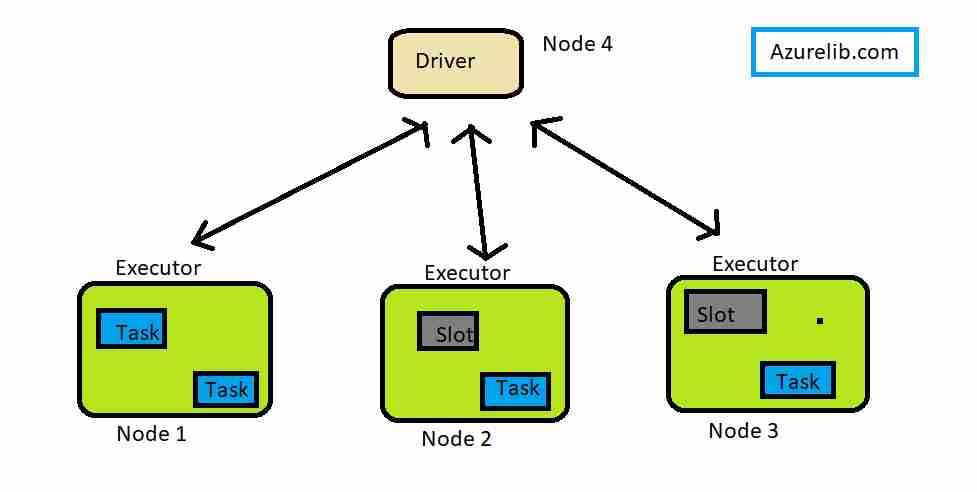
- The first level of parallelization is the Executor – a JVM running on a node, typically, one executor instance per node.
- The second level of parallelization is the Slot – the number of which is determined by the number of cores and CPUs of each node/executor.
SparkSession
It’s a unified object to perform all the Spark operations. In the earlier version of the Spark 1.x there were separate objects like SparkContext, SQLContext, HiveContext, SparkConf, and StreamingContext. However with Spark 2.x all these different objects combine into one i.e. the SparkSession. You can perform all those operations using the SparkSession object itself.
This unison of all the objects has made life simpler for the Spark Developers.
In the Spark standalone mode you have to manually create the Sparksession object however in the interactive spark-shell it will be given automatically with the global variable name ‘spark’.
Cluster Manager
As the name suggest it is responsible for managing the cluster. It also used to allocate the resources for the nodes available in the cluster.
Different types of the cluster managers are available as:
- Built-in standalone cluster manager,
- Apache Hadoop YARN,
- Apache Mesos
- Kubernetes
Spark Executor
A Spark executor is a program which runs on each worker node in the cluster. Executors communicate with the driver program and are responsible for executing tasks on the workers. In most deployments modes, only a single executor runs per node. In nutshell Executor do:
- Executing code assigned to it by the driver2666
- Reporting the state of the computation, on that executor, back to the driver node
- Each Executor has a number of Slots to which parallelized Tasks can be assigned to it by the Driver.
- So for example:
- If we have 3 identical home desktops (nodes) connected together having (8 cores) processors in each, then that’s a 3 node Cluster:
- 1 Driver node
- 2 Executor nodes
- The 8 cores per Executor node means 8 Slots, meaning the driver can assign each executor up to 8 Tasks
- The idea is, multicore processor is built such that it is capable of executing it’s own Task independent of the other Cores, so 8 Cores = 8 Slots = 8 Tasks in parellel
- If we have 3 identical home desktops (nodes) connected together having (8 cores) processors in each, then that’s a 3 node Cluster:
- So for example:
How to set number of slot, Task based on number of cores?
- All processors of today have multiple cores (e.g. 1 CPU = 8 Cores)
- Most processors of today are multi-threaded (e.g. 1 Core = 2 Threads, 8 cores = 16 Threads)
- A Spark Task runs on a Slot. 1 Thread is capable of doing 1 Task at a time. To make use of all our threads on the CPU, we cleverly assign the number of Slots to correspond to a multiple of the number of Cores (which translates to multiple Threads).
- For example: Assume that we have 4 Node in the cluster
Driver Node : 1
Worker node : 3 (i.e we have 3 executor node)
Assuming we have 8 core processor machine then slot = 3*8 = 24 Slot
Assuming multithreaded JVM with 2 thread per core processor = 3*8*2 = 48 thread slot
Hence in this cluster environment we can have 48 Tasks which can run on 48 Partitions.
You will try to keep your number of tasks equal to the number of slots available to avoid waiting time.
DataFrames
A DataFrame is the most common way to create the abstraction for data. It is the Structured API by Apache Spark which can represent the data as a table with rows and columns. The list of columns and the data types of those columns is called the schema.
Partitions
Dataframe used to hold the data on which you will apply the various operations like (filter, join, group by etc) however under the hood dataframe saved the data in multiple partitions.
Spark actually splits the data into multiple chunks which are called Partitions and stores the data physically on multiple machines.
A file gets divided into multiple chunks and stored as partitions on multiple machines. This has two advantages
- A very big file can get saved into a cluster otherwise it was difficult to store it on one machine.
- Each task will use each partition and run in parallel. This will help in achieving the parallelism.
You can manipulate the number of partitions as per the need. You don’t access the partition on an individual basis instead of that you will use the data frame and do operation on it.
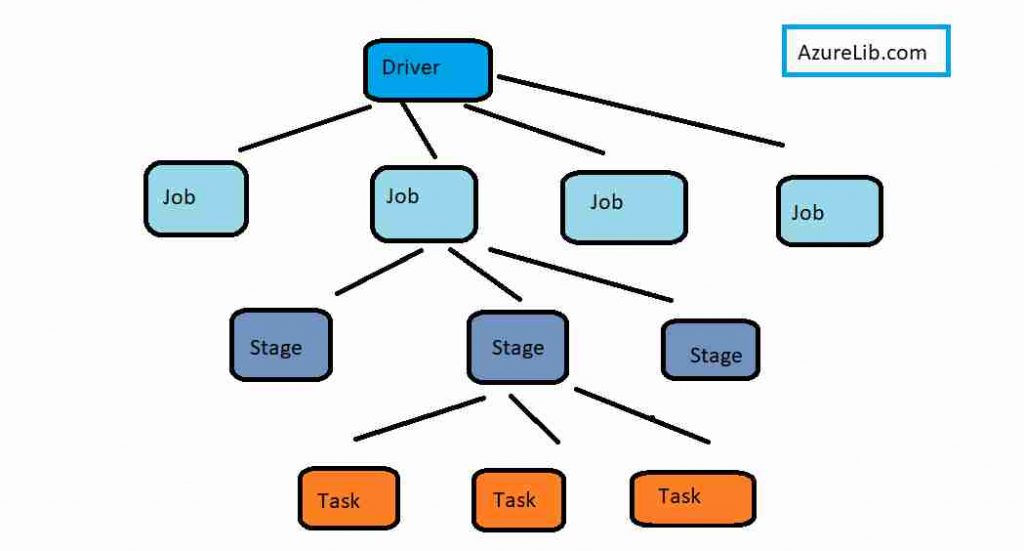
Job
Invoking an action inside a Spark application triggers the launch of a job to fulfill it. One spark application can have multiple jobs depending upon the code written.
Stage
Each job gets divided into smaller sets of tasks called stages that depend on each other. A stage is a collection of tasks that run the same code, each on a different subset of the data.
Tasks
Each stage is consist of multiple Spark tasks (a unit of execution), which is performed on Spark executor. Each task maps to a single core and works on a single partition of data.
Apache Spark Documentation Link
Final Thoughts
In this series of the Azure Databricks Spark tutorial we have covered the Apache Spark core concepts. We have learned:
| Cluster | Cluster is set of node(machines). |
| Sparksession | Sparksession object is the main object to run all spark operations. |
| SparkDriver | SparkDriver is associated with every Spark application which take care of whole application. |
| Spark Application | Spark Application divided in spark job which in turn divided in spark stage and further into spark task |
| Dataframe | Spark stores the data as dataframe which internally split into chunks and stored as partitions. |
I hope you have learned spark concepts by this post, please share your query, comments and feedback in the comment section below.
