
Creating dataframe in the Databricks is one of the starting step in your data engineering workload. In this blog post I will explain how you can create the Azure Databricks pyspark based dataframe from multiple source like RDD, list, CSV file, text file, Parquet file or may be ORC or JSON file. Let’s go step by step and understand how we can create dataframe from variety of data sources and formats.
Azure Databricks Spark Tutorial for beginner to advance level – Lesson 1
How to Create a Dataframe in Databricks ?
We can create a DataFrame in Databricks using toDF() and createDataFrame() methods, both of these function takes different signatures in order to create DataFrame from existing list, DataFrame and RDD.
We can also create DataFrame in Databricks from data sources like TXT, CSV, JSON, ORV, Avro, Parquet, XML formats by reading from Azure Blob file systems, HDFS, S3, DBFS e.t.c.
At last, DataFrame in Databricks also can be created by reading data from NoSQL databases and RDBMS Databases.
To create a DataFrame from a list we need the data. firstly, let’s create the data and the columns that are required.
columns = ["ID","Name"]
data = [("1", "John"), ("2", "Mist"), ("3", "Danny")]
1. Create a DataFrame from RDD in Azure Databricks pyspark
One best way to create DataFrame in Databricks manually is from an existing RDD. first, create a spark RDD from a collection List by calling parallelize() function. We would require this rdd object for our examples below.
spark = SparkSession.builder.appName('Azurelib.com').getOrCreate()
rdd = spark.sparkContext.parallelize(data)
1.1 Make Use of toDF() function in Datbricks
RDD’s toDF() method is used to create a DataFrame from existing RDD. Since RDD doesn’t have columns, the DataFrame will create with default column names “_1” and “_2” as we are having two columns.
dfFromRDD = rdd.toDF()
dfFromRDD.printSchema()
printschema() back down the below output.
root
|-- _1: string (nullable = true)
|-- _2: string (nullable = true)
If you wanted to provide column names to the DataFrame use toDF() method with column names as arguments as shown below.
columns = ["ID","Name"]
dfFromRDD = rdd.toDF(columns)
dfFromRDD.printSchema()
This capitulates schema of the DataFrame with column names.
root
|-- ID: string (nullable = true)
|-- Name: string (nullable = true)
By default, the datatype of these columns infers to the type of data. We can change this behavior by supplying schema, where we can specify a data type, column name and nullable for each field/column.
1.2 Using createDataFrame() from the SparkSession in Databricks
Using createDataFrame() from SparkSession is other way to create manually and it takes rdd object as an argument and chain with toDF() to specify name to the columns.
dfFromRDD1 = spark.createDataFrame(rdd).toDF(*columns)
2. Create a DataFrame from List Collection in Databricks
In this section, we will see how to create PySpark DataFrame from a list. These examples would be similar to what we have seen in the above section with RDD, but we use the list data object instead of “rdd” object to create DataFrame.
2.1 Using createDataFrame() from the SparkSession in Databricks
Calling createDataFrame() from SparkSession is another way to create PySpark DataFrame manually, it takes a list object as an argument. and chain with toDF() to specify names to the columns.
dfFromData1 = spark.createDataFrame(data).toDF(*columns)
2.2 Using createDataFrame() with the Row type in Databricks
createDataFrame() has another signature which takes the collection of Row type and schema for column names as arguments. To use this first we need to convert our “data” object from the list to list of Row.
rowData = map(lambda x: Row(*x), data)
dfFromData2 = spark.createDataFrame(rowData,columns)
2.3 Create DataFrame with the schema in Databricks
If we want to specify the column names along with their data types, you should create the StructType schema first and next we need to assign this while creating a DataFrame.
from pyspark.sql.types import StructType,StructField, StringType, IntegerType
data2 = [("James","","Smith","36636","M"),
("Michael","Rose","","40288","M"),
("Robert","","Williams","42114","M"),
("Maria","Anne","Jones","39192","F"),
("Jen","Mary","Brown","","F")
]
schema = StructType([ \
StructField("firstname",StringType(),True), \
StructField("middlename",StringType(),True), \
StructField("lastname",StringType(),True), \
StructField("id", StringType(), True), \
StructField("gender", StringType(), True), \
])
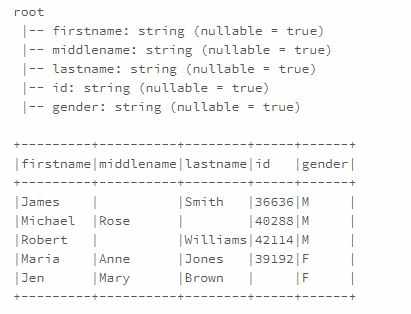
df = spark.createDataFrame(data=data2,schema=schema)
df.printSchema()
df.show(truncate=False)
This yields below output.
3. Create DataFrame from the Data sources in Databricks
In real-time mostly we create DataFrame from data source files like CSV, JSON, XML e.t.c.
PySpark by default supports many data formats out of the box without importing any libraries and to create DataFrame we need to use the appropriate method available in DataFrameReader class.
3.1 Creating DataFrame from a CSV in Databricks
Use csv() method of the DataFrameReader object to create a DataFrame from CSV file. you can also provide options like what delimiter to use, whether you have quoted data, date formats, infer schema, and many more.
df2 = spark.read.csv("/src/resources/file1.csv")
3.2. Creating from a text file in Databricks
Similarly you can also create a DataFrame by reading a from Text file, use text() method of the DataFrameReader to do so.
df2 = spark.read.text("/src/resources/file1.txt")
3.3. Creating from a JSON file in Databricks
PySpark is also used to process semi-structured data files like JSON format. you can use json() method of the DataFrameReader to read JSON file into DataFrame. Below is a simple example.
df2 = spark.read.json("/src/resources/file1.json")
Similarly, we can create DataFrame in PySpark from most of the relational databases which I’ve not covered here and I will leave this to you to explore.
4. Other sources (Avro, Parquet, ORC, Kafka) in Databricks
We can also create DataFrame by reading Avro, Parquet, ORC, Binary files and accessing Hive and HBase table, and also reading data from Kafka..
Databricks Official Documentation Link
Final Thoughts
Finally we reached to the end of this insightful article where we have learned how to create the dataframe in the Azure Databricks spark using the multiple data source of different formats.
- For Azure Study material Join Telegram group : Telegram group link:
- Azure Jobs and other updates Follow me on LinkedIn: Azure Updates on LinkedIn
- Azure Tutorial Videos: Videos Link
How to Select Columns From DataFrame in Databricks
How to Collect() – Retrieve data from DataFrame in Databricks
