
Azure Databricks or in general Databricks support the scala, R and python notebook. Now if you have your logic written in the Java language and wondering how to run the java code in the azure Databricks, you have reached the right place. In this blog we will discuss the ways to run the java in azure Databricks and see the Azure Databricks Java Example.
Databricks doesn’t support the Java notebook execution directly. You can only run the notebook in R, Python and Scala. However there are two ways in which you can run the java code on Azure Databricks cluster.
1. Create a jar of java code and import the jar in the Databircks cluster.
2. Use Databricks connect to integrate your eclipse with Databricks cluster.
Let’s dive into these two approaches to run the Azure Databricks java example as follows:
Azure Databricks Scenario based Interview Questions and Answers
Approach 1: Using java code as jar
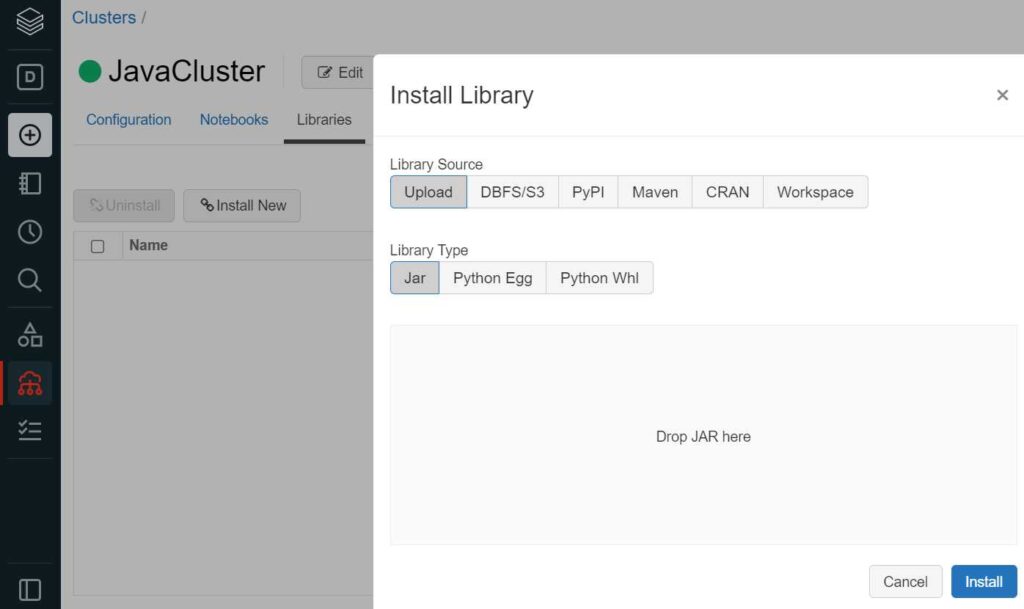
When you have java code for spark what you can do is, you can export the java code as an executable jar. In the jar file your whole code will be there. After that you can go to the Databricks cluster and go to the libraries and upload the jar file as a library there
Now you can have one notebook which is a SCALA notebook, there you can import the java classes from the libraries. Use these java classes and execute the SCALA notebook.
Approach 2: Using Databricks connect
In this approach there is no need to extract the java code as a jar. This is a little complex one time setup. Once you do the configuration then it will be a very smooth way to execute the Java spark code on Databricks cluster.
Databricks connect is the tool provided by Databricks Inc to integrate your local environment to run the workload over the Databricks cluster directly. It allows connecting IDE like Eclipse, IntelliJ, PyCharm, RStudio, Visual Studio to Databricks clusters.
It required Java Runtime Environment (JRE) 8. The client has been tested with the OpenJDK 8 JRE. The client does not support Java 11.
Command to install the Databricks connect and configure it.
pip install -U "databricks-connect==7.3.*" # or X.Y.* to match your cluster version.
databricks-connect configureAzure Databricks Java Example
Let’s have a small azure Databricks java example. There is as such no difference between the java code for the Databricks and the normal SPARK java code. You can also use the same Helloworld code of Java Spark.
Below is the complete code of Azure Databricks Java Example :
import java.util.ArrayList;
import java.util.List;
import java.sql.Date;
import org.apache.spark.sql.SparkSession;
import org.apache.spark.sql.types.*;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.RowFactory;
import org.apache.spark.sql.Dataset;
public class App {
public static void main(String[] args) throws Exception {
SparkSession spark = SparkSession
.builder()
.appName("Java Spark Demo")
.config("spark.master", "local")
.getOrCreate();
// Create a Spark DataFrame consisting of stock price with date and low and high
// price.
StructType schema = new StructType(new StructField[] {
new StructField("StockCode", DataTypes.StringType, false, Metadata.empty()),
new StructField("Date", DataTypes.DateType, false, Metadata.empty()),
new StructField("highPrice", DataTypes.IntegerType, false, Metadata.empty()),
new StructField("lowPrice", DataTypes.IntegerType, false, Metadata.empty()),
});
List<Row> dataList = new ArrayList<Row>();
dataList.add(RowFactory.create("Apple", Date.valueOf("2021-07-13"), 20, 12));
dataList.add(RowFactory.create("Twitter", Date.valueOf("2021-07-13"), 40, 35));
dataList.add(RowFactory.create("MS", Date.valueOf("2021-07-13"), 60, 53));
dataList.add(RowFactory.create("Google", Date.valueOf("2021-07-13"), 76, 65));
Dataset<Row> stock= spark.createDataFrame(dataList, schema);
spark.sql("USE default");
spark.sql("DROP TABLE IF EXISTS stock_table");
stock.write().saveAsTable("stock_table");
// Query the table on the Databricks cluster, returning rows
// where the airport code is not BLI and the date is later
// than 2021-04-01. Group the results and order by high
// temperature in descending order.
Dataset<Row> df_stock = spark.sql("SELECT * FROM stock_table");
df_stock .show();
}
}Final Thought:
There is no difference bewteen the Java Databricks code and the plain spark code written in java. Databricks is simply just a cloud infrastructure provider to run your spark workload with some add on capability.
