
It is one of the very interesting post for the people who are looking to crack the data engineer or data scientist interview. In this blog post I will take you through handful of databricks interview questions and answers to test your knowledge and helps you to prepare for interviews in better way. In these set of questions focus would be real time scenario based questions, azure databricks interview questions for freshers, azure databricks interview questions for experienced professionals, interview questions for databricks developer and interview questions for databricks architect.
Get Crack Azure Data Engineer Interview Course
– 125+ Interview questions
– 8 hrs long Pre- recorded video course
– Basic Interview Questions with video explanation
– Tough Interview Questions with video explanation
– Scenario based real world Questions with video explanation
– Practical/Machine/Written Test Interview Q&A
– Azure Architect Level Interview Questions
– Cheat sheets
– Life time access
– Continuous New Question Additions
Here is the link to get Azure Data Engineer prep Course
Question 1: How would you create the Azure Databricks workspace.
You need to login to azure portal. Once you logged in, search the ‘databricks’ in the top bar and click on the azure databricks in the drop down. If you don’t have any other azure databricks workspace then you will see empty screen like below. Click on the ‘+’ to create the new workspace.
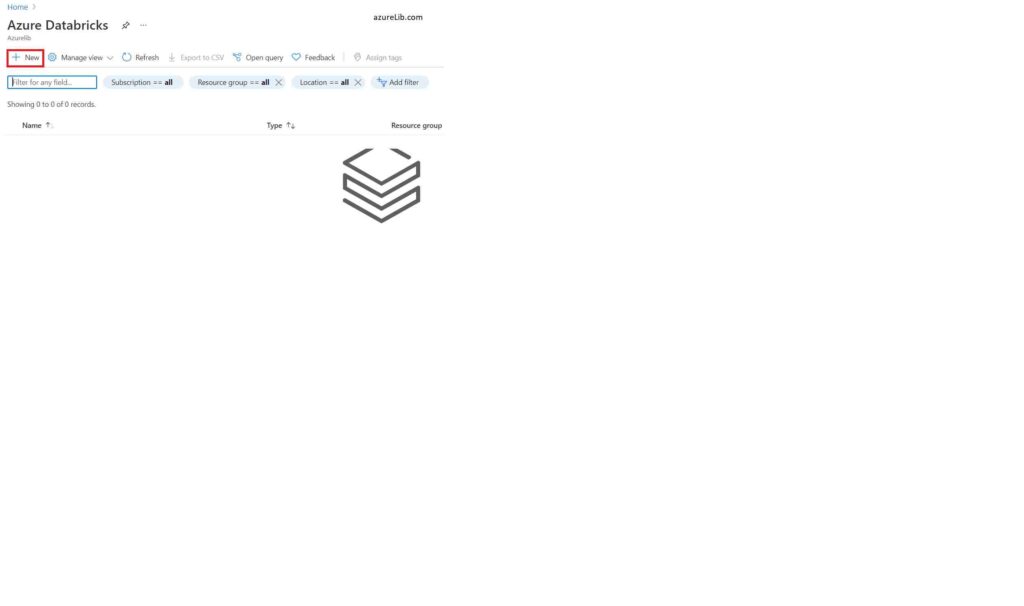
Provide the details like name of the azure databricks workspace, resource group, subscription, region in which you want to create the workspace and the pricing tier of the azure databricks.
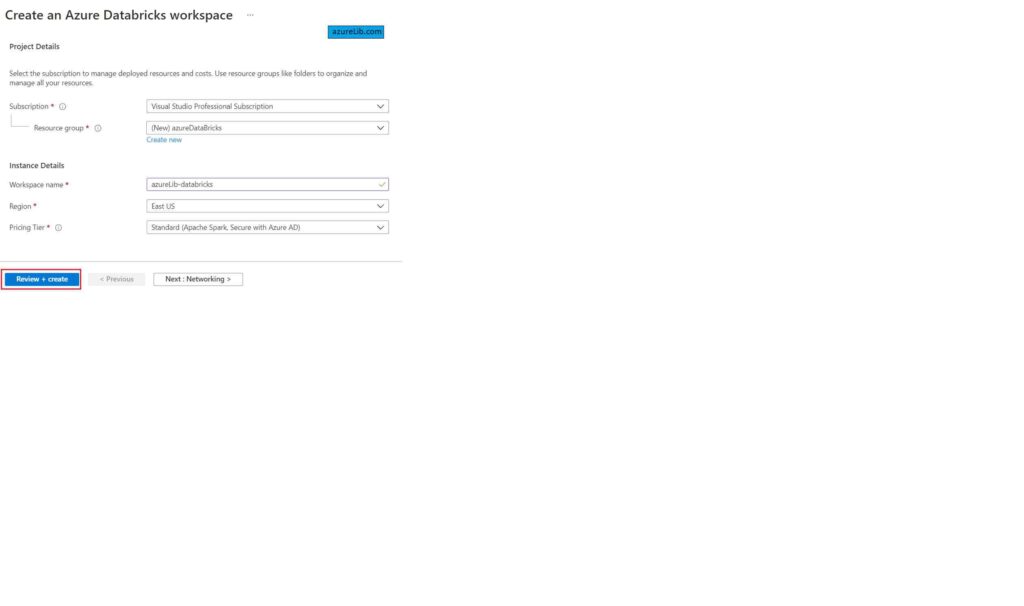
This is how you can create your azure databricks workspace.
Azure data factory scenario based interview questions and answers
Question 2: What are the different pricing tier of the azure databricks available ?
There are basically two tier provided by the azure for databricks service :
Get Crack Azure Data Engineer Interview Course
– 125+ Interview questions
– 8 hrs long Pre- recorded video course
– Basic Interview Questions with video explanation
– Tough Interview Questions with video explanation
– Scenario based real world Questions with video explanation
– Practical/Machine/Written Test Interview Q&A
– Azure Architect Level Interview Questions
– Cheat sheets
– Life time access
– Continuous New Question Additions
Here is the link to get Azure Data Engineer prep Course
Question 3: Assume that you have newly started working for XYZ company. Your manager has asked you to write some business analytics logic in the azure notebook by reusing the some of the generic functionality code developed by other team member. How would you do it?
I would highly recommend to go through this quick video as well , as it has explained the Azure Databricks concepts in very well manner, which would definitely help you in interview.
AZURE DATABRICKS Quick Concepts video:
Whenever we want to reuse the code in databricks, we need to import that code in our notebook. Now importing the code can also be done in two ways. Assume that if the code is available in same workspace we may be able to directly import them. If code is outside of the workspace, in that case you may need to create jar/module of it and import the jar or the module in the databricks cluster.
- For Azure Study material Join Telegram group : Telegram group link:
- Azure Jobs and other updates Follow me on LinkedIn: Azure Updates on LinkedIn
- Azure Tutorial Videos: Videos Link

Question 4: How to import third party jars or dependencies in the Databricks?
Sometimes while writing your code, you may needed the various third party dependencies. If you are using the databricks in the SCALA language then you may need the external jars, otherwise you are using the databricks in python then you may need to import the external module.
You need to understand that the importing of the dependency not happened at the notebook level however it happened over the cluster level. You have to add the external dependencies (jar/module) to the cluster runtime environment.
Go to the cluster and select the libraries. Under the libraries you will see ‘Install new ‘ tab click on it. Now it will ask for the type and source of the library to be installed. Provide the details and click on the Install.
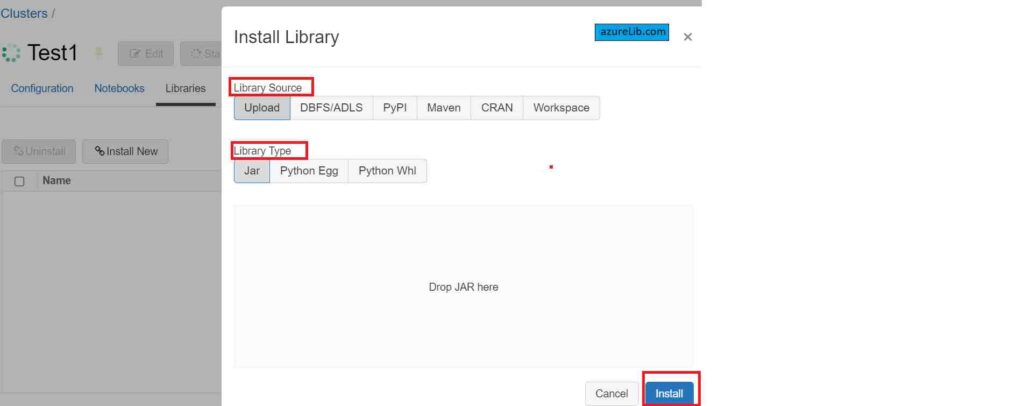
This way you will be able to use external dependencies in the azure notebook.
Question 5: How to connect the azure storage account in the Databricks?
For performing the data analytics in databricks where the data source is the azure storage, in that scenario we need the way to connect the azure storage to the databricks. Once this connection is done we can load the file in data frame like a normal operation and can continue writing our code.
To connect the azure blob storage in the databricks, you need to mount the azure stoarge container in the databricks. This needed to be done once only. Once the mounting is done, we can starting access the files from azure blob storage using the mount directory name. For creating the mount you need to provide the SAS token, storage account name and container name.
dbutils.fs.mount(
source = "wasbs://<container-name>@<storage-account-name>.blob.core.windows.net",
mount_point = "/mnt/<mount-name>",
extra_configs = {"<conf-key>":dbutils.secrets.get(scope = "<scope-name>", key = "<key-name>")})- <container-name> is the name of the container to which you want to connect.
- <storage-account-name> is the name of the storage account which you want to connect.
- <mount-name>is a DBFS path representing where the Blob storage container or a folder inside the container (specified in
source) will be mounted in DBFS - <conf-key> it can be
fs.azure.account.key.<storage-account-name>.blob.core.windows.netorfs.azure.sas.<container-name>.<storage-account-name>.blob.core.windows.netor you can use the secrets from key store
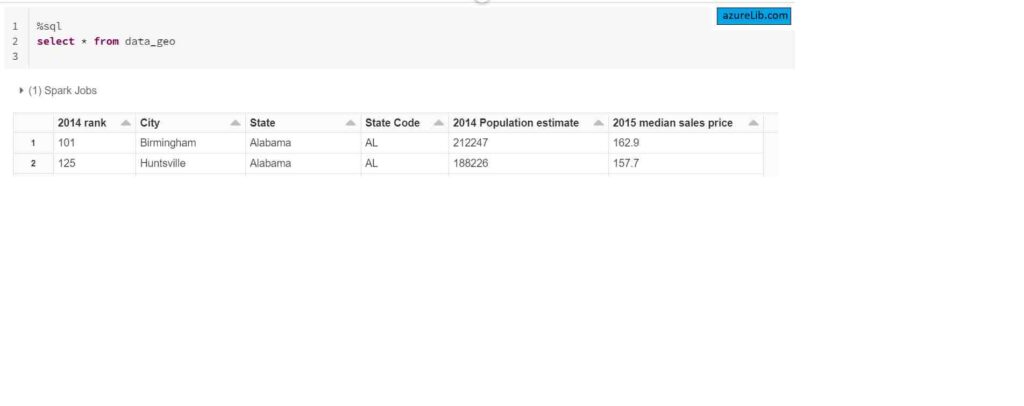
Question 6: How to run the sql query in the python or the scala notebook without using the spark sql?
In the databricks notebook you case use the ‘%sql’ at the start of the any block, that will make the convert the python/scala notebook into the simple sql notebook for that specific block.
Question 7: What is the Job in Databricks?
Job is the way to run the task in non-interactive way in the Databricks. It can be used for the ETL purpose or data analytics task. You can trigger the job by using the UI , command line interface or through the API. You can do following with the Job :
- Create/view/delete the job
- You can do Run job immediately.
- You can schedule the job also.
- You can pass the parameters while running the job to make it dynamic.
- You can set the alerts in the job, so that as soon as the job gets starts, success or failed you can receive the notification in the form of email.
- You can set the number of retry for the failed job and the retry interval.
- While creating the job you can add all the dependencies and can define which cluster to be used for executing the job.
Question 8: How many different types of cluster mode available in the Azure Databricks?
Azure Databricks provides the three type of cluster mode :
- Standard Cluster: This is intended for single user. Its can run workloads developed in any language: Python, R, Scala, and SQL.
- High Concurrency Cluster: A High Concurrency cluster is a managed cloud resource. It provide Apache Spark-native fine-grained sharing for maximum resource utilization and minimum query latencies. High Concurrency clusters work only for SQL, Python, and R. The performance and security of High Concurrency clusters is provided by running user code in separate processes, which is not possible in Scala.
- Single Node Cluster: A Single Node cluster has no workers and runs Spark jobs on the driver node.
Question 9: How can you connect your ADB cluster to your favorite IDE (Eclipse, IntelliJ, PyCharm, RStudio, Visual Studio)?
Databricks connect is the way to connect the databricks cluster to local IDE on your local machine. You need to install the dataricks-connect client and then needed the configuration details like ADB url, token etc. Using all these you can configure the local IDE to run and debug the code on the cluster.
pip install -U "databricks-connect==7.3.*" # or X.Y.* to match your cluster version.
databricks-connect configureGet Crack Azure Data Engineer Interview Course
– 125+ Interview questions
– 8 hrs long Pre- recorded video course
– Basic Interview Questions with video explanation
– Tough Interview Questions with video explanation
– Scenario based real world Questions with video explanation
– Practical/Machine/Written Test Interview Q&A
– Azure Architect Level Interview Questions
– Cheat sheets
– Life time access
– Continuous New Question Additions
Here is the link to get Azure Data Engineer prep Course
Question 10: How typical Azure Databricks CI/CD pipeline consist of?
Like basic concepts of the any azure devops CI/CD pipeline for the azure databricks also it consists of :
Continuous integration: Write and develop the code, test cases in the azure notebook once all looks good commit the code in the GIT branch. Build the code and libraries. Gather new and updated code and tests. Generate a release artifact.
Continuous delivery: Deploy the notebook and libraries and run if there any automated test cases. Programmatically schedule data engineering, analytics, and machine learning workflows.
Mostly asked Azure Data Factory Interview Questions and Answers
You would also like to see these interview questions as well for your Azure Data engineer Interview :
Azure Databricks Spark Tutorial
Real time Azure Data factory Interview Questions and Answers
Azure Devops Interview Questions and Answers
Azure Data lake Interview Questions and Answers
Azure Active Directory Interview Questions and Answers
Final Thoughts:
In this blog I have tried to assemble up couple of azure databricks interview questions and answers. This is one of the very important guide for freshers and experienced professional databricks developer. I haven’t included the questions based on spark, my main focus was to cover the databricks part specifically. I have tried to add up the questions based on the real world working scenario.
