
In this Azure Data engineer series I am going to share the most frequently asked interview question for freshers and experienced professional upto 2,3,4,5,6,7,8,9,10 + years. Azure synapse analytics is one of the popular service for the Azure Data engineer professional hence if you are planning to make a career as Azure data engineer, then it is one of the must to have skillset in your resume. In these set of questions focus would be real time scenario based questions, azure synapse analytics interview questions for freshers, azure azure synapse analytics interview questions for experienced professionals, interview questions for azure synapse developer and interview questions for azure data architect. I have also covered the real time and real world scenarios based Azure Synapse analytics interview questions and answers in this preparation guide.
Assume that you are working as a data engineer lead. You wanted to go and check how many SQL requests have been executed so far in the SQL pool by your team. Where you can go and check all the historical queries executed in the Azure synapse Analytics workspace?
Whenever you run any query in the Azure synapse Analytics the history log has been created for that query. You have to go to the manage tab and there you can see the SQL request. You can filter out based on the time and see all the execution with their results.
Assume that you are working as a data engineer lead and there are couple of spark notebook that has been executed in last one hour. You wanted to go and check all those notebook executions. Where you can go and check the history of the last one hour and download the event log for them in the Azure synapse Analytics?
You have to go to the monitor tab. In the monitor tab on the left-hand side, you have the activities section. Under it, there is a tab for the Azure spark application. Click on it and in the adjacent blade you will see Spark history server. Just click on that and there you will see the entire history and from there you can download the event log for specific application run.
Get Crack Azure Data Engineer Interview Course
– 125+ Interview questions
– 8 hrs long Pre- recorded video course
– Basic Interview Questions with video explanation
– Tough Interview Questions with video explanation
– Scenario based real world Questions with video explanation
– Practical/Machine/Written Test Interview Q&A
– Azure Architect Level Interview Questions
– Cheat sheets
– Life time access
– Continuous New Question Additions
Here is the link to get Azure Data Engineer prep Course
How to recover the data when you delete the external table?
Whenever you delete the external table your data won’t get deleted because we just point to the data location in the external table. Data will still be there on the referenced location. Here you have to just recreate the external table, pointing to the same location and you will be able to access the data once again.
Assume that you are working for Azurelib.com as a data engineer. Azurelib.com wanted to move its data from an on-premise server to the Azure cloud. You want to do this using Azure synapse Analytics. How you can do this? Explain.
Moving the data from an on-premise server to the cloud server we have to create an integration runtime. This integration runtime would be the self hosted IR. Because autoresolve integration runtime (default IR provided by the Azure) can’t connect to the on-prem servers. Once you have created the self hosted IR, then we can create a pipeline using the copy activity that will move the data from the on-premise server to the cloud server.

Assume that you are working as data engineer lead in Azurelib.com. You have decided to leave the organization therefore to replace you a new data engineer lead has joined the team. You are the owner of the Azure synapse Analytics workspace. Now you have to make this newly joined lead also as the owner of your workspace how would you do it explain.
For making the new lead as an owner of Azure synapse Analytics workspace we have to assign him an owner role. Go to the Azure portal. In the Azure portal search for the azure synapse workspace and open it. In the left hand side pane, you will see IAM (Identity access management) link. Click and open it. Now you have to add a role assignment. In the add role assignment select the role as ‘Owner’, assign it to as ‘User’ and select the member (newly joined lead) and save. This will assign the owner role for Azure synapse analytics to a newly joined lead.
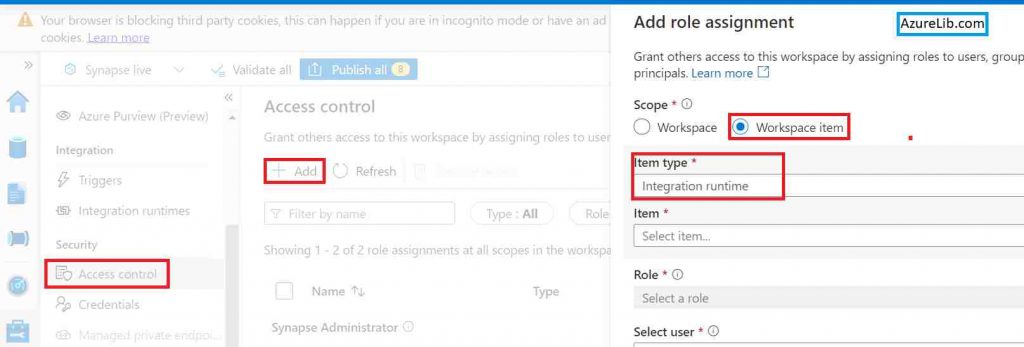
Assume that you are working as data engineer lead in Azurelib.com which is moving from on-prem to cloud. Azurelb.com has some mission critical data on one of their on-prem server. Hence you have to ensure that only selected team members within the team have access to self hosted IR which you have created for it. How you can achieve this requirement in Azure synapse analytics.
Go to Azure synapse analytics workspace studio. Under the monitor tab, go to the access control. There you can provide access at the workspace item level. Select the item as IR and the name of the IR, role, and member detail.
Assume that you are working as a data engineer developer in Azurelib.com. You have asked to run some algorithms using the apache spark pool of the Azure synapse analytics. This code uses the third party library as well. How you can ensure that this third party library jars are added to the apache spark pool.
In the Azure synapse analytics workspace go to the manage tab. Create a workspace, in the workspace upload the jar files (third part code library jars). Go back to the apache Spark pool right click on it and select package. In the package select the workspace which contains the jar and click on apply. Now restart your spark pool. This will ensure that these third party libraries are getting access to the notebook execution code.
Assume that you are working as a data architect in Azurelib.com. There is another application that is going to access the data generated by your stored procedure of SQL pool database. This data need to be updated on daily basis. How would you solve this problem?
First, you need to create the pipeline into the integration tab of the resource in the Azure synapse Analytics workspace. In this pipeline, we have to add SQL pool stored procedure activity. In the SQL pool stored procedure activity, select the designated stored procedure. Now schedule this pipeline by adding the trigger which will run this pipeline on daily basis.
Assume that you are working as a data engineer lead having a team of 10 members. Multiple team members are working on the synapse analytics workspace. How can you track the changes done by team members?
You can configure the workspace with GIT this will ensure that all the changes will be tracked.
Assume that you are working as a data architect in Azurelib.com. There is another application that is sending the data into the cloud azure data lake storage folder location. Once this data is available inside this folder you have to run the algorithm, which will analyze the data using the apache spark code. How you can architect the solution for this scenario.
Spark job has to be executed once the file is available in the folder location that means we want to trigger the job using the storage event. Hence to solve this problem we have to create one Spark job which contains your algorithm. Next, we have to create a pipeline that executes the Spark job. Lastly, we have to create the storage event trigger for this pipeline which will execute this pipeline as soon as the other application drops the file into the specified folder location.
What is the linked service in Azure synapse Analytics?
Linked Services is used to make a connection to the external sources outside the Azure synapse Analytics workspace. For example, if you want to connect to the Azure data lake storage account to run the SQL queries on the files. Or maybe you have data available in the on-prem server and you want to pull this data into the cloud. Then to make a connection you have to create a linked service by providing the details like user name, password server address.
What are the different types of SQL pools available in Azure synapse Analytics?
There are two types of SQL pool available in the Azure synapse Analytics
Serverless SQL pool
Dedicated SQL pool
What is the dedicated SQL pool in Azure synapse Analytics?
Whenever you have to run the SQL query in the Azure synapse Analytics you need the computation power to run this query. SQL pool provides the computation power to run your queries. You create the dedicated SQL pool by deciding the computation power you need based on your requirement. It will keep on charging you until and unless you stop this SQL pool. Because it is a dedicated reservation of resources for your SQL pool. It also provides you a database where you can create tables external tables for procedures as per the business need.
What is the default SQL pool in Azure synapse Analytics?
There is a serverless SQL pool available in the Azure synapse Analytics whenever you create the Azure synapse Analytics workspace. This is a default SQL pool available for use and it is called as built in serverless SQL pool.
What is Apache Spark pool in Azure synapse Analytics?
Azure synapse Analytics provides basically two types of services first is to run the SQL queries and the second is to run the Apache Spark code. Whenever you have to run the spark code in order to run some logic you need the cluster where you can go and execute this code. This execution power is provided by the Apache spark pool. There is no default Spark book available in the Azure synapse Analytics. You have to go in and create one Spark pool minimum to run Spark code.
What is the open rowset function in Azure synapse Analytics?
Rowset function is used to read the file as a table. For example, there is a file stored in the ADLSaccount and you want to run the queries on this file. You can read this file as a table using the rowset function which will give every row of a file as a row of a table.
Write a query to read the csv file as a table in the Azure synapse Analytics?
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://rohitmrggenstg.dfs.core.windows.net/demoqueries/Order.csv',
FORMAT = 'CSV',
PARSER_VERSION='2.0'
) AS [result]What are the different distribution techniques while you ingest the data in SQL dedicated pool?
- Hash
- Round Robin
- Replicate
What is the control node in the Azure synapse Analytics
Control is the heart of the SQL pool architecture. Distributed query engine runs on the Control node to optimize and coordinate parallel queries. When you submit a T-SQL query to a dedicated SQL pool, the Control node transforms it into queries that run against each distribution in parallel.
In a serverless SQL pool, the DQP engine runs on the Control node to optimize and coordinate distributed execution of user queries by splitting them into smaller queries that will be executed on Compute nodes. It also assigns sets of files to be processed by each node
What is the trigger in the Azure synapse analytics?
In many cases, you wanted to schedule the pipeline run. Triggers are used to schedule the automatic execution of the pipeline. There are multiple types of triggers available in the synapse like time based schedule trigger, storage event trigger, custom event trigger, and tumbling window trigger.
Get Crack Azure Data Engineer Interview Course
– 125+ Interview questions
– 8 hrs long Pre- recorded video course
– Basic Interview Questions with video explanation
– Tough Interview Questions with video explanation
– Scenario based real world Questions with video explanation
– Practical/Machine/Written Test Interview Q&A
– Azure Architect Level Interview Questions
– Cheat sheets
– Life time access
– Continuous New Question Additions
Here is the link to get Azure Data Engineer prep Course
How to create a pipeline in the Azure synapse analytics.
In the Azure synapse Analytics there is integrate tab. In the integrate tab, you can create the pipeline just like you can create the people in the Azure data factory. Here you find all the activities which are available in the actual data factory to cerate the pipeline like copy activity, for each activity, custom activity, and many more other activities. One of the specific activity which is available inside the integrate tab is synapse activity which is not available in the ADF.
How to create the spark job into the Azure synapse analytics?
Azure synapse Analytics workspace studio, I have to go to the develop tab and under the develop tab you can create the apache spark job definition. You click on it and then you provide all the details need to create the job like your JAR file name, your class name, where your job gets executed. Once you provided all the required information click Save. This will create your Spark job.
How to schedule the spark job in the Azure synapse analytics.
First, you have to create the apache spark job under the develop tab. Now we have to go to the integrate tab and there you to create the pipeline. In the pipeline select the spark job activity and add it to the pipeline. Now configure the spark job activity by selecting the specific spark job which you want to schedule. Lastly, just schedule this pipeline and it will simply schedule your Spark job.
Microsoft Official Documentation Azure Synapse Link
Recommendations
Most of the Azure Data engineer finds it little difficult to understand the real world scenarios from the Azure Data engineer’s perspective and faces challenges in designing the complete Enterprise solution for it. Hence I would recommend you to go through these links to have some better understanding of the Azure Data factory.
Azure Data Engineer Real World scenarios
Azure Databricks Spark Tutorial for beginner to advance level
Latest Azure DevOps Interview Questions and Answers
You can also checkout and pinned this great Youtube channel for learning Azure Free by industry experts
Final thoughts
In this blog, I have tried to assemble up a couple of Azure synapse Analytics interview questions and answers. This is one of the very important guides for freshers and experienced professional Azure data engineer developers and leads. In this list of interview preparation guide my main focus was to cover all the question which is frequently and mostly asked on Azure synapse Analytics. databricks part specifically. I have tried to add up the questions based on the real world working scenario.
Hope you have liked this Interview preparation guide and will help you to crack the Azure Data Engineer interview. You can also go through my various interview preparation guide for Azure data factory, Azure data bricks, Azure data analytics, and many more.
Please share your suggestions and feedback and you can ask your question and update this guide based on your interview experience.
