
1. What is azure data factory used for ?
Azure Data factory is the data orchestration service provided by the Microsoft Azure cloud. ADF is used for following use cases mainly :
- Data migration from one data source to other
- On Premise to cloud data migration
- ETL purpose
- Automated the data flow.
There is huge data laid out there and when you want to move the data from one location to another in automated way within the cloud or from on-premises to the azure cloud azure data factory is the best service we have available.

2. What are the main components of the azure data factory ?
These are the main components of the the azure data factory:
3. What is the pipeline in the adf ?
Pipeline is the set of the activities specified to run in defined sequence. For achieving any task in the azure data factory we create a pipeline which contains the various types of activity as required for fulfilling the business purpose. Every pipeline must have a valid name and optional list of parameters.
Real-time Scenario Based Interview Questions for Azure Data Factory
4. What is the data source in the azure data factory ?
It is the source or destination system which contains the data to be used or operate upon. Data could be of anytype like text, binary, json, csv type files or may be audio, video, image files, or may be a proper database. Data source examples are : Azure blob storage, azure data lake storage, any database like azure sql database, mysql db, postgres and etc. There are 80+ different data source connector provided by the azure data factory to get in/out data from the data source.
5. What is the integration runtime in Azure data factory :
It is the powerhouse of the azure data pipeline. Integration runtime is also knows as IR, is the one who provides the computer resources for the data transfer activities and for dispatching the data transfer activities in azure data factory. Integration runtime is the heart of the azure data factory.
In Azure data factory the pipeline is made up of activities. An activity is represents some action that need to be performed. This action could be a data transfer which acquired some execution or it will be dispatch action. Integration runtime provides the area where this activity can execute.
6. What are the different types of integration runtime ?
There are 3 types of the integration runtime available in the Azure data factory. We can choose based upon our requirement the specific integration runtime best fitted in specific scenario. The three types are :
- Azure IR
- Self-hosted
- Azure-SSIS
7. What is Azure Integration Runtime ?
As the name suggested azure integration runtime is the runtime which is managed by the azure itself. Azure IR represents the infrastructure which is installed, configured, managed and maintained by the azure itself. Now as the infrastructure is managed by the azure it can’t be used to connect to your on premise data sources. Whenever you create the data factory account and create any linked services you will get one IR by default and this is called AutoResolveIntegrationRuntime.
When you create the azure data factory you mentioned the region along with it. This region specifies where the meta data of the azure data factory would be saved. This is irrespective of the which data source and from which region you are accessing.
For example if you have created the adf account in the US East and you have data source in US West region, then still it is completely ok and data transfer would be possible.
8. What is the main advantage of the AutoResolveIntegrationRuntime ?
Advantage of AutoResolveIntegrationRuntime is that it will automatically try to run the activities in the same region if possible or close to the region of the sink data source. This can improve the performance a lot.
9. What is Self Hosted Integration Runtimes in azure data factory?
Self hosted integration runtime as the name suggested, is the IR managed by you itself rather than azure. This will make you responsible for the installation, configuration, maintenance, installing updates and scaling. Now as you host the IR , it can access the on premises network as well.
10. What is the Azure-SSIS Integration Runtimes
As the name suggested the azure-SSIS integration runtimes are actually the set of vm running the SQL Server Integration Services (SSIS) engine, managed by Microsoft. Again the responsibility of the installation, maintenance, are of azure only. Azure Data Factory uses azure-SSIS integration runtime for executing SSIS packages.
11. How to install Self Hosted Integration Runtimes in azure data factory ?
Steps to install the self-hosted integration runtime is as follows :
1. Create self hosted integration runtime by simply giving general information like name description.
2. Create Azure VM (If u already have then you can skip this step)
3. Download the integration runtime software on azure virtual machine. and install it.
4. Copy the autogenerated key from step 1 and paste it newly installed integration runtime on azure vm.
12. What is use of lookup activity in azure data factory ?
Lookup activity in adf pipeline is generally used for configuration lookup purpose. It has the source dataset. Lookup activity used to pull the data from source dataset and keep it as the output of the activity. Output of the lookup activity generally used further in the pipeline for making some decision, configuration accordingly.
You can say that lookup activity in adf pipelines is just for fetching the data. How you will use this data will totally depends on your pipeline logic. You can fetch first row only or you can fetch the entire rows based on your query or dataset.
Example of the lookup activity could be : Lets assume we want to run a pipeline for incremental data load. We want to have copy activity which will pull the data from source system based on the last fetched date. Now the last fetched date we are saving inside the HighWaterMark.txt file. Here lookup activity will read the HighWaterMark.txt data and then based on the date copy activity will fetch the data.
13. What is copy activity in azure data factory
Copy activity is one of the most popular and highly used activity in the azure data factory.
Copy activity is basically used for ETL purpose or lift and shift where you want to move the data from one data source to the other data source. While you copy the data you can also do the transformation for example you read the data from csv file which contains 10 columns however while writing to your target data source you want to keep only 5 columns. You can transform it and you can send only the required number of columns to the the destination data source.
For creating the copy activity you need to have your source and destination ready. Here destination is called as sink. Copy activity requires:
- Linked service
- Datasets
Assume you already have a linked service and data service created in case not you can please refer these links to create link service and datasets
How to create Linked service in Azure data factory
What is dataset in azure data factory
14. What do you mean by variables in the azure data factory ?
Variables is the adf pipeline provide the functionality to temporary hold the values. They are used for similar reason like we do use variables in the programming language. They are available inside the pipeline and there is set inside the pipeline. Set Variable and append variable are two type of activities used for the setting or manipulating the variables values. There are two types of the variable :
System variable: These are some kind of the fixed variable from the azure pipeline itself. For example pipeline name, pipeline id, trigger name etc. You mostly need this to get the system information which might be needed in your use case.
User variable : User variable is something which you declared manually based on your logic of the pipeline.
15. What is the linked service in the azure data factory ?
Linked service in azure data factory are basically the connection mechanism to connect to the external source. It works as the connection string to hold the user authentication information.
For example you want to connect to copy the data from the azure blob storage to azure sql server. In this case you need to build the 2 Linked service. One which is connect to blob storage and other to connect to azure sql database.
There are two ways to create the Linked Service :
- Using the Azure Portal
- ARM template way
16. What is the Dataset in the adf ?
In azure data factory as we create the data pipelines for ETL / Shift and load / Analytics purpose we need to create the dataset. Dataset connects to the datasource via linked service. It is created based upon the type of the data and data source you want to connect. Dataset resembles the type of the data holds by data source.
For example if we want to pull the csv file from the azure blob storage in the copy activity, we need linked service and the dataset for it. Linked service will be used to make connection to the azure blob storage and dataset would hold the csv type data.
17. Can we debug the pipeline ?
Debugging is one of the key feature for any developer. To solve and test issue in the code developers uses the debug feature in general. Azure data factory also provide the debugging feature. In this tutorial I will take you through each and every minute details which would help you to understand the debug azure data factory pipeline feature and how you can utilize the same in your day to day work.
When you go to the data pipeline tab there on the top you can see the ‘Debug’ link to click. Like this :
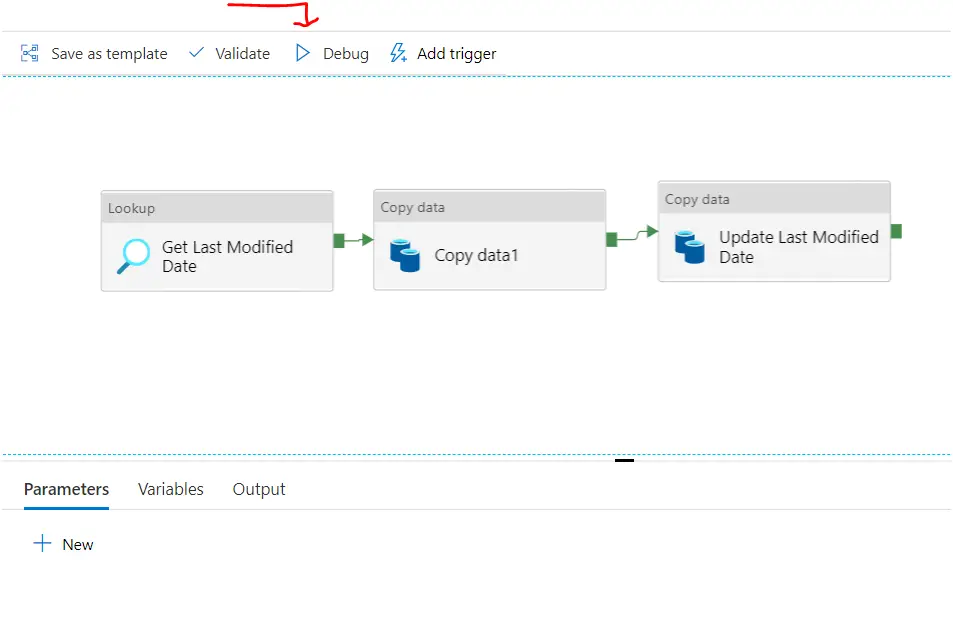
When you click on the Debug it will start running the pipeline like you are executing it. Its not testing. If you are doing deleting the data or inserting the data in your pipeline activity, it will get update respectively. Debugging the pipeline can make permanent change.
Warning : Do not consider the pipeline debugging just as testing it will impact immediately to your data based on the type of activity.
However you can use the ‘Preview‘ option available in some of the activity, that is available for the read purpose only.
18. What is the breakpoint in the adf pipeline ?
Debug part of the pipeline using the break points : While doing if you want to check the pipeline up to certain activity you can do it by using the breakpoints.
For example you have 3 activities in the pipeline and you want to debug up to 2nd activity only. You can do this by putting the break point at the 2nd activity. There is circle on the top of the activity you can just click to add break point :
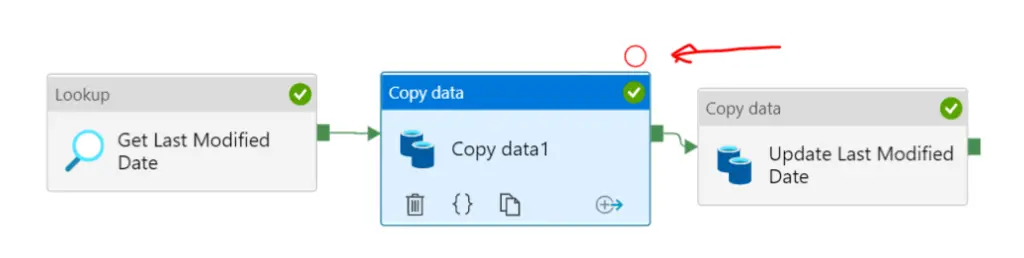
Once you click the hollow red circle you can see next activity will get disables and hollow circle converted to filled one :
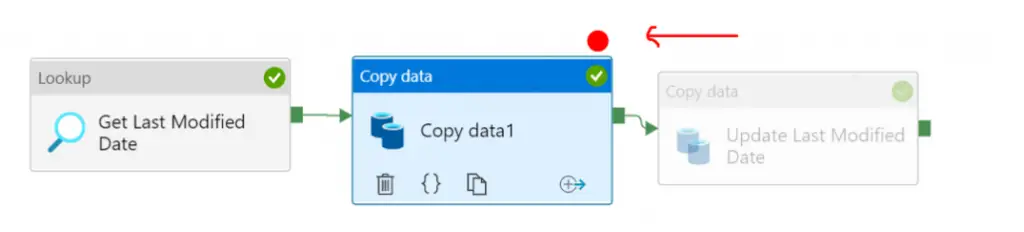
Now if you debug the pipeline it will get executed up to breakpoint only.
You would also like to see these interview questions as well for your Azure Data engineer Interview :
Azure Databricks Spark Tutorial
Real time Azure Data factory Interview Questions and Answers
Azure Devops Interview Questions and Answers
Azure Data lake Interview Questions and Answers
