
You must have come across a couple of posts about the Azure data factory interview questions and answer but none of them has been talking about the real-time scenario-based Azure data factory interview questions and answers. In this post, I will take you through the Azure data factory real-time scenario and Azure databricks interview questions answers for experienced Azure data factory developer.
Question 1 : Assume that you are a data engineer for company ABC The company wanted to do cloud migration from their on-premises to Microsoft Azure cloud. You probably will use the Azure data factory for this purpose. You have created a pipeline that copies data of one table from on-premises to Azure cloud. What are the necessary steps you need to take to ensure this pipeline will get executed successfully?
The company has taken a very good decision of moving to the cloud from the traditional on-premises database. As we have to move the data from the on-premise location to the cloud location we need to have an Integration Runtime created. The reason being the auto-resolve Integration runtime provided by the Azure data factory cannot connect to your on-premises. Hence in step 1, we should create our own self-hosted integration runtime. Now this can be done in two ways:
The first way is we can have one virtual Machine ready in the cloud and there we will install the integration runtime of our own.
The second way, we could take a machine on the on-premises network and install the integration runtime there.
Once we decided on the machine where integration runtime needs to be installed (let’s take the virtual machine approach). You need to follow these steps for Integration runtime installation.
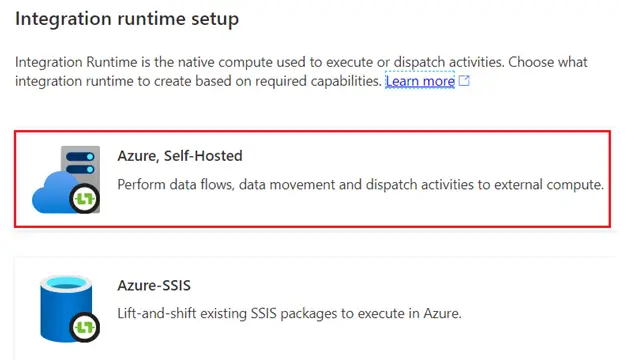
- Go to the azure data factory portal. In the manage tab select the Integration runtime.
- Create self hosted integration runtime by simply giving general information like name description.
- Create Azure VM (If u already have then you can skip this step)
- Download the integration runtime software on azure virtual machine. and install it.
- Copy the autogenerated key from step 2 and paste it newly installed integration runtime on azure vm.
You can follow this link for detailed step by step guide to understand the process of how to install sefl-hosted Integration runtime. How to Install Self-Hosted Integration Runtime on Azure vm – AzureLib
Once your Integration runtime is ready we go to linked service creation. Create the linked service which connect to the your data source and for this you use the integration runtime created above.
After this we will create the pipeline. Your pipeline will have copy activity where source should be the database available on the on-premises location. While sink would be the database available in the cloud.
Once all of these done we execute the pipeline and this will be the one-time load as per the problem statement. This will successfully move the data from a table on on-premises database to the cloud database.
You can also find this pdf very useful.

Question 2: Assume that you are working for a company ABC as a data engineer. You have successfully created a pipeline needed for migration. This is working fine in your development environment. how would you deploy this pipeline in production without making any or very minimal changes?
When you create the pipeline for migration or for any other purposes like ETL, most of the time it will use the data source. In the above mentioned scenario, we are doing the migration hence it is definitely using a data source at the source side and similarly a data source at the destination side and we need to move the data from source to destination. It is also described in the in the question itself data engineer has developed the pipeline successfully in the development environment. Hence it is safe to assume that source side data source and destination side data source both probably will be pointing to the development environment only. Pipeline would have copy activity which uses the dataset with the help of linked service for source and sink.
Linked service provides way to connect to the data source by providing the data source details like the server address, port number, username, password, key, or other credential related information.
In this case, our linked services probably pointing to the development environment only.
As we want to do production deployment before that we may need to do a couple of other deployments as well like deployment for the testing environment or UAT environment.
Hence we need to design our Azure data factory pipeline components in such a way that we can provide the environment related information dynamic and as a part of a parameter. There should be no hard coding of these kind of information.
We need to create the arm template for our pipeline. ARM template needs to have a definition defined for all the constituents of the pipeline like Linked services, dataset, activities and pipeline.
Once the ARM template is ready, it should be checked-in into the GIT repository. Lead or Admin will create the devops pipeline which will take up this arm template and parameter file as an input. Devops pipeline will deploy this arm template and create all the resources like linked service, dataset, activities and your data pipeline into the production environment.
- For Azure Study material Join Telegram group : Telegram group link:
- Azure Jobs and other updates Follow me on LinkedIn: Azure Updates on LinkedIn
- Azure Tutorial Videos: Videos Link
Question 3: Assume that you have around 1 TB of data stored in Azure blob storage . This data is in multiple csv files. You are asked to do couple of transformations on this data as per business logic and needs, before moving this data into the staging container. How would you plan and architect the solution for this given scenario. Explain with the details.
First of all, we need to analyze the situation. Here if you closely look at the size of the data, you find that it is very huge in the size. Hence directly doing the transformation on such a huge size of data could be very cumbersome and time consuming process. Hence we should think about the big data processing mechanism where we can leverage the parallel and distributed computing advantages.. Here we have two choices.
- We can use the Hadoop MapReduce through HDInsight capability for doing the transformation.
- We can also think of using the spark through the Azure databricks for doing the transformation on such a huge scale of data.
Out of these two, Spark on Azure databricks is better choice because Spark is much faster than Hadoop due to in memory computation. So let’s choose the Azure databricks as the option.
Next we need to create the pipeline in Azure data factory. A pipeline should use the databricks notebook as an activity.
We can write all the business related transformation logic into the Spark notebook. Notebook can be executed using either python, scala or java language.
When you execute the pipeline it will trigger the Azure databricks notebook and your analytics algorithm logic runs an do transformations as you defined into the Notebook. In the notebook itself, you can write the logic to store the output into the blob storage Staging area.
That’s how you can solve the problem statement.
Get Crack Azure Data Engineer Interview Course
– 125+ Interview questions
– 8 hrs long Pre- recorded video course
– Basic Interview Questions with video explanation
– Tough Interview Questions with video explanation
– Scenario based real world Questions with video explanation
– Practical/Machine/Written Test Interview Q&A
– Azure Architect Level Interview Questions
– Cheat sheets
– Life time access
– Continuous New Question Additions
Here is the link to get Azure Data Engineer prep Course
Question 4: Assume that you have an IoT device enabled on your vehicle. This device from the vehicle sends the data every hour and this is getting stored in a blob storage location in Microsoft Azure. You have to move this data from this storage location into the SQL database. How would design the solution explain with reason.
This looks like an a typical incremental load scenario. As described in the problem statement, IoT device write the data to the location every hour. It is most likely that this device is sending the JSON data to the cloud storage (as most of the IoT device generate the data in JSON format). It will probably writing the new JSON file every time whenever the data from the device sent to the cloud.
Hence we will have couple of files available in the storage location generated on hourly basis and we need to pull these file into the azure sql database.
we need to create the pipeline into the Azure data factory which should do the incremental load. we can use the conventional high watermark file mechanism for solving this problem.
Highwater mark design is as follows :
- Create a file named lets say HighWaterMark.txt and stored in some place in azure blob storage. In this file we will put the start date and time.
- Now create the pipeline in the azure data factory. Pipeline has the first activity defined as lookup activity. This will read the date from the HighWaterMark.txt
- Add a one more lookup activity which will return the current date time.
- Add the copy activity in the pipeline which will pull the file JSON files having created timestamp greater than High Water Mark date. In the sink push the read data into the azure sql database.
- After copy activity add the another copy activity which will update the current date time generated in the step 2, to the High Water Mark file.
- Add the trigger to execute this pipeline on hourly basis.
That’s how we can design the incremental data load solution for the above described scenario.

Question 5: Assume that you are doing some R&D over the data about the COVID across the world. This data is available by some of the public forum which is exposed as REST api. How would you plan the solution in this scenario?
You would also like to see these interview questions as well for your Azure Data engineer Interview :
Azure Devops Interview Questions and Answers
Azure Data lake Interview Questions and Answers
Azure Active Directory Interview Questions and Answers
Azure Databricks Spark Interview Questions and Answers
Azure Data Factory Interview Questions and Answers
I would recommend you to must this YouTube channel once, there is very good source available on azure data factory and Azure.
Final Thoughts :
Azure data factory is the new field and due to this there is shortage of resources available on the internet which needed for preparing for azure data factory (adf) interviews. In this blog I tried to provide many real world scenario based interview questions and answers for experienced adf developer and professionals. I will on adding few more questions in near time I would recommend you, to also grow the theoretical questions sum up in this linked article. Here : Mostly asked Azure Data Factory Interview Questions and Answers
